Coffea Histograms (deprecated)
This feature is deprecated in favor of hist and mplhep. A migration guide can be found in discussion CoffeaTeam/coffea#705
This is a rendered copy of histograms.ipynb. You can optionally run it interactively on binder at this link
In scientific python, histograms seem to be considered as a plot style, on equal footing with, e.g. scatter plots. It may well be that HEP is the only place where users need to plot pre-binned data, and thus must use histograms as persistent objects representing reduced data. In Coffea, the hist subpackage provides a persistable mergable histogram object. This notebook will discuss a few ways that such objects can be manipulated.
A histogram object roughly goes through three stages in its life:
Filling
Transformation (projection, rebinning, integrating)
Plotting
We’ll go over examples of each stage in this notebook, and conclude with some styling examples.
Filling
Let’s start with filling. We’ll use a random distribution near and dear to of b and c factory physicists, and have the numpy builtin histogram function do the work for us:
[1]:
import numpy as np
from scipy.stats import argus
vals = argus(chi=.5).rvs(size=1000)
hist = np.histogram(vals)
print(hist)
(array([ 16, 47, 66, 95, 125, 113, 137, 167, 143, 91]), array([0.002894 , 0.10257766, 0.20226132, 0.30194498, 0.40162865,
0.50131231, 0.60099597, 0.70067963, 0.80036329, 0.90004695,
0.99973061]))
So we’re done, right? Probably not: we have more than 1000 events, and probably need to use some map-reduce paradigm to fill the histogram because we can’t keep all 1 billion vals in memory. So we need two things: a binning, so that all histograms that were independently created can be added, and the ability to add two histograms.
[2]:
binning = np.linspace(0, 1, 50)
def add_histos(h1, h2):
h1sumw, h1binning = h1
h2sumw, h2binning = h2
if h1binning.shape == h2binning.shape and np.all(h1binning==h2binning):
return h1sumw+h2sumw, h1binning
else:
raise ValueError("The histograms have inconsistent binning")
[3]:
vals2 = argus(chi=.5).rvs(size=1000)
hist1 = np.histogram(vals, bins=binning)
hist2 = np.histogram(vals, bins=binning)
hist = add_histos(hist1, hist2)
print(hist)
(array([ 2, 6, 6, 6, 12, 18, 20, 16, 14, 28, 22, 26, 28, 42, 18, 34, 28,
48, 40, 42, 42, 60, 46, 62, 46, 52, 46, 38, 52, 54, 50, 58, 72, 54,
50, 74, 80, 58, 70, 70, 42, 64, 68, 52, 60, 32, 44, 30, 18]), array([0. , 0.02040816, 0.04081633, 0.06122449, 0.08163265,
0.10204082, 0.12244898, 0.14285714, 0.16326531, 0.18367347,
0.20408163, 0.2244898 , 0.24489796, 0.26530612, 0.28571429,
0.30612245, 0.32653061, 0.34693878, 0.36734694, 0.3877551 ,
0.40816327, 0.42857143, 0.44897959, 0.46938776, 0.48979592,
0.51020408, 0.53061224, 0.55102041, 0.57142857, 0.59183673,
0.6122449 , 0.63265306, 0.65306122, 0.67346939, 0.69387755,
0.71428571, 0.73469388, 0.75510204, 0.7755102 , 0.79591837,
0.81632653, 0.83673469, 0.85714286, 0.87755102, 0.89795918,
0.91836735, 0.93877551, 0.95918367, 0.97959184, 1. ]))
So now we have everything we need to make our own equivalent to ROOT TH1, from a filling perspective:
[4]:
class myTH1:
def __init__(self, binning):
self._binning = binning
self._sumw = np.zeros(binning.size - 1)
def fill(self, values, weights=None):
sumw, _ = np.histogram(values, bins=self._binning, weights=weights)
self._sumw += sumw
def __add__(self, other):
if not isinstance(other, myTH1):
raise ValueError
if not np.array_equal(other._binning, self._binning):
raise ValueError("The histograms have inconsistent binning")
out = myTH1(self._binning)
out._sumw = self._sumw + other._sumw
return out
[5]:
binning = np.linspace(0, 1, 50)
h1 = myTH1(binning)
h1.fill(vals)
h2 = myTH1(binning)
h2.fill(vals2)
h = h1 + h2
print(h._sumw)
[ 3. 3. 7. 5. 9. 18. 16. 17. 15. 24. 26. 27. 34. 37. 23. 38. 29. 46.
40. 40. 36. 50. 47. 49. 57. 49. 50. 44. 59. 69. 55. 52. 68. 54. 48. 72.
72. 64. 55. 74. 57. 64. 63. 55. 49. 39. 39. 31. 22.]
Homework: add sumw2 support.
Of course, we might want multidimensional histograms. There is np.histogramdd:
[6]:
xyz = np.random.multivariate_normal(mean=[1, 3, 7], cov=np.eye(3), size=10000)
xbins = np.linspace(-10, 10, 20)
ybins = np.linspace(-10, 10, 20)
zbins = np.linspace(-10, 10, 20)
hnumpy = np.histogramdd(xyz, bins=(xbins, ybins, zbins))
but we are becoming challenged by book-keeping of the variables. The histogram class in Coffea is designed to simplify this operation, and the eventual successor (for filling purposes) boost-histogram has similar syntax.
In the constructor you specify each axis, either as a numeric Bin axis or a categorical Cat axis. Each axis constructor takes arguments similar to ROOT TH1 constructors. One can pass an array to the Bin axis for non-uniform binning. Then the fill call is as simple as passing the respective arrays to histo.fill.
[7]:
import coffea.hist as hist
histo = hist.Hist("Counts",
hist.Cat("sample", "sample name"),
hist.Bin("x", "x value", 20, -10, 10),
hist.Bin("y", "y value", 20, -10, 10),
hist.Bin("z", "z value", 20, -10, 10),
)
histo.fill(sample="sample 1", x=xyz[:,0], y=xyz[:,1], z=xyz[:,2])
# suppose we have another sample of xyz values
xyz_sample2 = np.random.multivariate_normal(mean=[1, 3, 7], cov=np.eye(3), size=10000)
# additionally, lets assume entries in sample 2 have some non-uniform weight equal to atan(distance from origin)
weight = np.arctan(np.sqrt(np.power(xyz_sample2, 2).sum(axis=1)))
# weight is a reserved keyword in Hist, and can be added to any fill() call
histo.fill(sample="sample 2", x=xyz_sample2[:,0], y=xyz_sample2[:,1], z=xyz_sample2[:,2], weight=weight)
print(histo)
<Hist (sample,x,y,z) instance at 0x7fa15cf61390>
[8]:
# For more details, look at:
# help(hist.Hist)
# help(hist.Bin)
# help(hist.Cat)
Transformation
Here are a few examples of transformations on multidimensional histograms in Coffea. For each, the docstring (help(function) or shift+tab in Jupyter) provides useful info.
[9]:
# sum all x bins within nominal range (-10, 10)
histo.sum("x", overflow='none')
[9]:
<Hist (sample,y,z) instance at 0x7fa15ba1af10>
There is some analog to fancy array slicing for histogram objects, which is supported (with reasonable consistency) in Coffea, where the slice boundaries are physical axis values, rather than bin indices. All values outside the slice range are merged into overflow bins.
For a lengthy discussion on possible slicing syntax for the future, see boost-histogram#35.
[10]:
sliced = histo[:,0:,4:,0:]
display(sliced)
display(sliced.identifiers("y", overflow='all'))
<Hist (sample,x,y,z) instance at 0x7fa15de8e650>
[<Interval ((-inf, 4)) instance at 0x7fa15ea2c710>,
<Interval ([4, 5)) instance at 0x7fa15ea2c790>,
<Interval ([5, 6)) instance at 0x7fa15ea2c7d0>,
<Interval ([6, 7)) instance at 0x7fa15ea2c810>,
<Interval ([7, 8)) instance at 0x7fa15ea2c850>,
<Interval ([8, 9)) instance at 0x7fa15ea2c8d0>,
<Interval ([9, 10)) instance at 0x7fa15ea2c910>,
<Interval ([10, inf)) instance at 0x7fa15ea2c950>]
[11]:
# integrate y bins from -2 to +10
histo.integrate("y", slice(0, 10))
[11]:
<Hist (sample,x,z) instance at 0x7fa15ea2cd50>
[12]:
# rebin z axis by providing a new axis definition
histo.rebin("z", hist.Bin("znew", "rebinned z value", [-10, -6, 6, 10]))
[12]:
<Hist (sample,x,y,znew) instance at 0x7fa15eb2d710>
[13]:
# merge categorical axes
mapping = {
'all samples': ['sample 1', 'sample 2'],
'just sample 1': ['sample 1'],
}
histo.group("sample", hist.Cat("cat", "new category"), mapping)
[13]:
<Hist (cat,x,y,z) instance at 0x7fa15eb307d0>
[14]:
# scale entire histogram by 3 (in-place)
histo.scale(3.)
[15]:
# scale samples by different values (also in-place)
scales = {
'sample 1': 1.2,
'sample 2': 0.2,
}
histo.scale(scales, axis='sample')
[16]:
# useful debugging tool: print bins, aka 'identifiers'
display(histo.identifiers('sample'))
display(histo.identifiers('x'))
[<StringBin (sample 1) instance at 0x7fa15e7ab7d0>,
<StringBin (sample 2) instance at 0x7fa15e7ab810>]
[<Interval ([-10, -9)) instance at 0x7fa15ceadfd0>,
<Interval ([-9, -8)) instance at 0x7fa15ceadd90>,
<Interval ([-8, -7)) instance at 0x7fa15cead350>,
<Interval ([-7, -6)) instance at 0x7fa15cead750>,
<Interval ([-6, -5)) instance at 0x7fa15ceadb50>,
<Interval ([-5, -4)) instance at 0x7fa15cead1d0>,
<Interval ([-4, -3)) instance at 0x7fa15ceade90>,
<Interval ([-3, -2)) instance at 0x7fa15cead250>,
<Interval ([-2, -1)) instance at 0x7fa15ceada90>,
<Interval ([-1, 0)) instance at 0x7fa15cead210>,
<Interval ([0, 1)) instance at 0x7fa15cead090>,
<Interval ([1, 2)) instance at 0x7fa15cead710>,
<Interval ([2, 3)) instance at 0x7fa15cead610>,
<Interval ([3, 4)) instance at 0x7fa15cead0d0>,
<Interval ([4, 5)) instance at 0x7fa15bec6710>,
<Interval ([5, 6)) instance at 0x7fa15ce87f90>,
<Interval ([6, 7)) instance at 0x7fa15eb361d0>,
<Interval ([7, 8)) instance at 0x7fa15eb36250>,
<Interval ([8, 9)) instance at 0x7fa15eb36310>,
<Interval ([9, 10)) instance at 0x7fa15eb363d0>]
[17]:
# bin contents are accessed using values
histo.sum('x', 'y').values(sumw2=False)
[17]:
{('sample 1',): array([0.00000e+00, 0.00000e+00, 0.00000e+00, 0.00000e+00, 0.00000e+00,
0.00000e+00, 0.00000e+00, 0.00000e+00, 0.00000e+00, 0.00000e+00,
0.00000e+00, 0.00000e+00, 3.60000e+00, 5.40000e+01, 7.23600e+02,
4.83120e+03, 1.24164e+04, 1.24344e+04, 4.68720e+03, 8.13600e+02]),
('sample 2',): array([0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,
7.67352230e-01, 1.23975181e+01, 1.91084135e+02, 1.16950599e+03,
3.00209800e+03, 2.88614286e+03, 1.20687727e+03, 1.68492970e+02])}
[18]:
# data can be exported to ROOT via uproot3 (soon uproot v4 as well), but only 1D
import uproot3
import os
if os.path.exists("output.root"):
os.remove("output.root")
outputfile = uproot3.create("output.root")
h = histo.sum('x', 'y')
for sample in h.identifiers('sample'):
outputfile[sample.name] = hist.export1d(h.integrate('sample', sample))
outputfile.close()
/Users/lagray/miniconda3/envs/coffea-work/lib/python3.7/site-packages/uproot3/__init__.py:138: FutureWarning: Consider switching from 'uproot3' to 'uproot', since the new interface became the default in 2020.
pip install -U uproot
In Python:
>>> import uproot
>>> with uproot.open(...) as file:
...
FutureWarning
Plotting
The most integrated plotting utility in the scientific python ecosystem, by far, is matplotlib. However, as we will see, it is not tailored to HEP needs.
Let’s start by looking at basic mpl histogramming.
[19]:
%matplotlib inline
import matplotlib.pyplot as plt
[20]:
vals = argus(chi=.5).rvs(size=1000)
# notice the semicolon, which prevents display of the return values
plt.hist(vals);
Suppose we want to plot pre-binned data, for example from our earlier np.histogram usage. Here we start running into the edge of typical mpl usage. As mentioned before, apparently HEP is the only regular user of pre-binned histograms.
[21]:
binning = np.linspace(0, 1, 50)
h1vals, h1bins = np.histogram(vals, bins=binning)
plt.step(x=h1bins[:-1], y=h1vals, where='post');
To facilitate these operations, there is a package called mplhep. This package is available standlaone, but it is also used internally by the coffea.hist subpackage to provide several convenience functions to aid in plotting Hist objects:
plot1d: Create a 1D plot from a 1D or 2D Hist object
plotratio: Create a ratio plot, dividing two compatible histograms
plot2d: Create a 2D plot from a 2D Hist object
plotgrid: Create a grid of plots, enumerating identifiers on up to 3 axes
Below are some simple examples of using each function on our histo object.
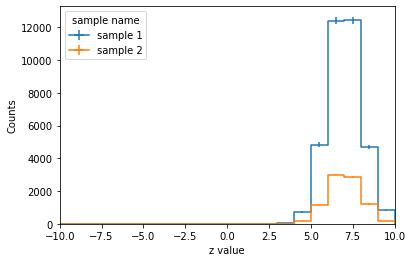
[22]:
hist.plot1d(histo.sum("x", "y"), overlay='sample');
[23]:
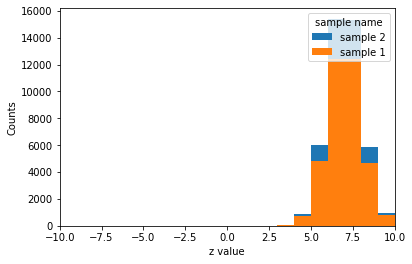
hist.plot1d(histo.sum("x", "y"), overlay='sample', stack=True);
[24]:
hist.plot2d(histo.sum('x', 'sample'), xaxis='y');

[25]:
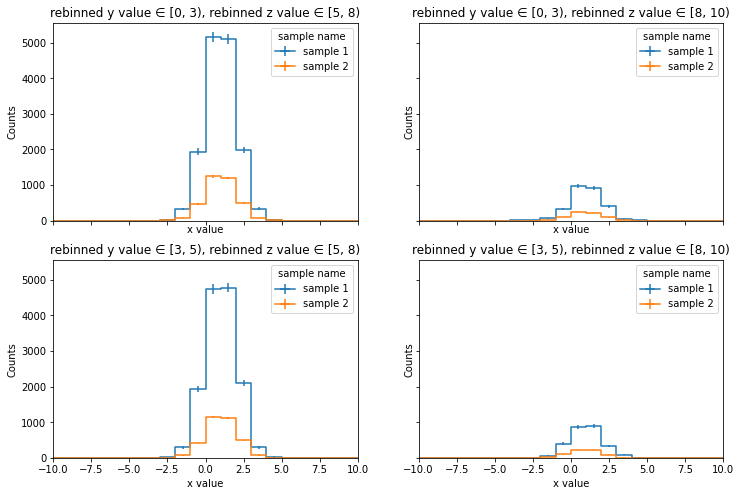
# make coarse binned hist and look at several distributions
hnew = (
histo
.rebin("y", hist.Bin("ynew", "rebinned y value", [0, 3, 5]))
.rebin("z", hist.Bin("znew", "rebinned z value", [5, 8, 10]))
)
hist.plotgrid(hnew, row='ynew', col='znew', overlay='sample');
[26]:
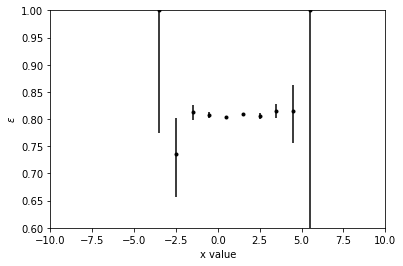
numerator = histo.integrate('sample', 'sample 1').sum('y', 'z')
denominator = histo.sum('sample', 'y', 'z')
numerator.label = r'$\epsilon$'
ax = hist.plotratio(
num=numerator,
denom=denominator,
error_opts={'color': 'k', 'marker': '.'},
unc='clopper-pearson'
)
ax.set_ylim(0.6, 1.)
ax.set_xlim(-10, 10)
/Users/lagray/coffea/coffea/binder/coffea/hist/plot.py:357: RuntimeWarning: invalid value encountered in true_divide
rsumw = sumw_num / sumw_denom
[26]:
(-10.0, 10.0)
Styling
We’ve covered the basics of plotting, now let’s go over some styling options. To make things more interesting, we’ll load some electron and muon Lorentz vectors from simulated \(H\rightarrow ZZ^{*}\) events into awkward arrays and then plot some kinematic quantities for them, making liberal use of the matplotlib styling options which are exposed through the coffea plotting utilities.
[27]:
!curl -OL http://scikit-hep.org/uproot3/examples/HZZ.root
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 212k 100 212k 0 0 7601k 0 --:--:-- --:--:-- --:--:-- 7601k
[28]:
import uproot
import awkward as ak
from coffea.nanoevents.methods import vector
ak.behavior.update(vector.behavior)
fin = uproot.open("HZZ.root")
tree = fin["events"]
# let's build the lepton arrays back into objects
# in the future, some of this verbosity can be reduced
arrays = {k.replace('Electron_', ''): v for k, v in tree.arrays(filter_name="Electron_*", how=dict).items()}
electrons = ak.zip({'x': arrays.pop('Px'),
'y': arrays.pop('Py'),
'z': arrays.pop("Pz"),
't': arrays.pop("E"),
},
with_name="LorentzVector"
)
arrays = {k.replace('Muon_', ''): v for k,v in tree.arrays(filter_name="Muon_*", how=dict).items()}
muons = ak.zip({'x': arrays.pop('Px'),
'y': arrays.pop('Py'),
'z': arrays.pop("Pz"),
't': arrays.pop("E"),
},
with_name="LorentzVector"
)
print("Avg. electrons/event:", ak.sum(ak.num(electrons))/tree.num_entries)
print("Avg. muons/event:", ak.sum(ak.num(muons))/tree.num_entries)
Avg. electrons/event: 0.07063197026022305
Avg. muons/event: 1.579925650557621
[29]:
lepton_kinematics = hist.Hist(
"Events",
hist.Cat("flavor", "Lepton flavor"),
hist.Bin("pt", "$p_{T}$", 19, 10, 100),
hist.Bin("eta", "$\eta$", [-2.5, -1.4, 0, 1.4, 2.5]),
)
# Pass keyword arguments to fill, all arrays must be flat numpy arrays
# User is responsible for ensuring all arrays have same jagged structure!
lepton_kinematics.fill(
flavor="electron",
pt=ak.flatten(electrons.pt),
eta=ak.flatten(electrons.eta)
)
lepton_kinematics.fill(
flavor="muon",
pt=ak.flatten(muons.pt),
eta=ak.flatten(muons.eta)
)
[30]:
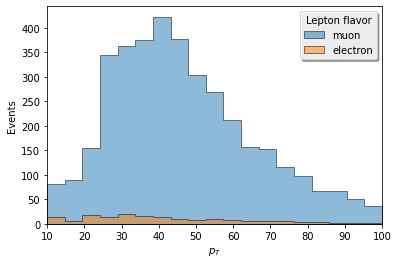
# Now we can start to manipulate this single histogram to plot different views of the data
# here we look at lepton pt for all eta
lepton_pt = lepton_kinematics.integrate("eta")
ax = hist.plot1d(
lepton_pt,
overlay="flavor",
stack=True,
fill_opts={'alpha': .5, 'edgecolor': (0,0,0,0.3)}
)
# all plot calls return the matplotlib axes object, from which
# you can edit features afterwards using matplotlib object-oriented syntax
# e.g. maybe you really miss '90s graphics...
ax.get_legend().shadow = True
[31]:
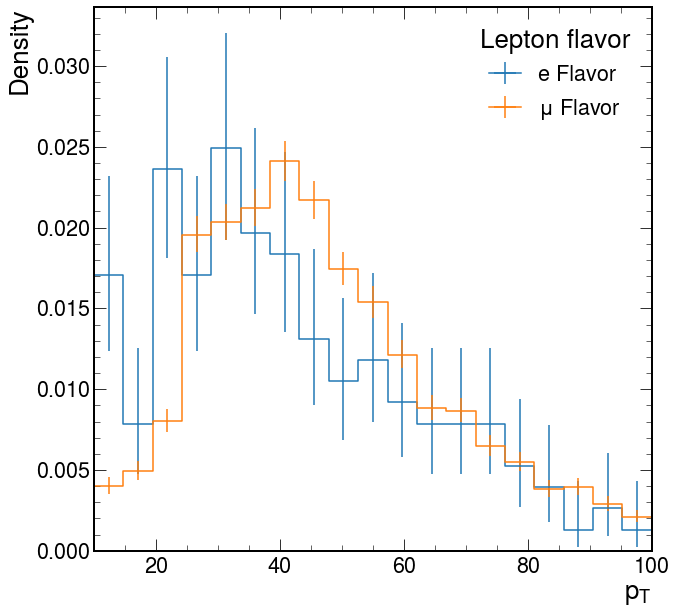
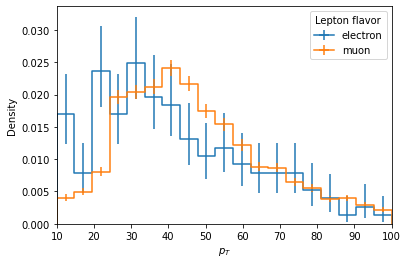
# Clearly the yields are much different, are the shapes similar? We can check by setting `density=True`
lepton_pt.label = "Density"
ax = hist.plot1d(lepton_pt, overlay="flavor", density=True)
[32]:
# Let's stack them, after defining some nice styling
stack_fill_opts = {
'alpha': 0.8,
'edgecolor':(0,0,0,.5)
}
stack_error_opts = {
'label':'Stat. Unc.',
'hatch':'///',
'facecolor':'none',
'edgecolor':(0,0,0,.5),
'linewidth': 0
}
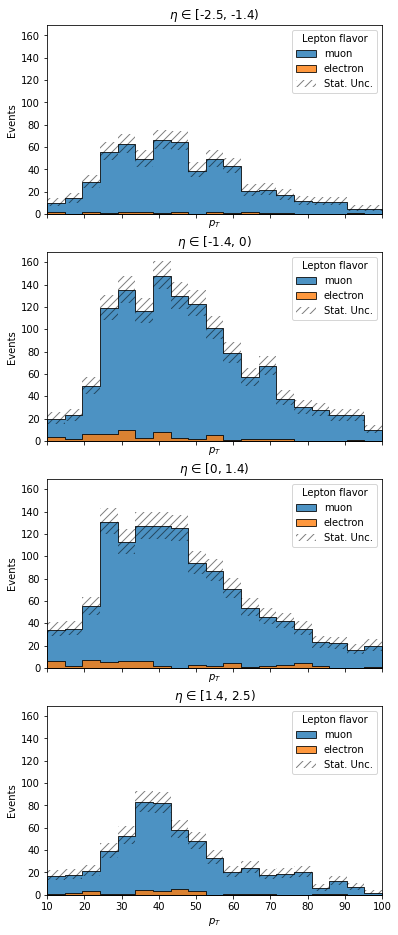
# maybe we want to compare different eta regions
# plotgrid accepts row and column axes, and creates a grid of 1d plots as appropriate
ax = hist.plotgrid(
lepton_kinematics,
row="eta",
overlay="flavor",
stack=True,
fill_opts=stack_fill_opts,
error_opts=stack_error_opts,
)
[33]:
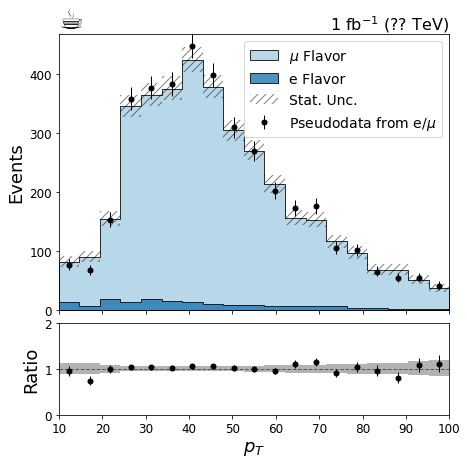
# Here we create some pseudodata for the pt histogram so we can make a nice data/mc plot
pthist = lepton_kinematics.sum('eta')
bin_values = pthist.axis('pt').centers()
poisson_means = pthist.sum('flavor').values()[()]
values = np.repeat(bin_values, np.random.poisson(poisson_means))
pthist.fill(flavor='pseudodata', pt=values)
# Set nicer labels, by accessing the string bins' label property
pthist.axis('flavor').index('electron').label = 'e Flavor'
pthist.axis('flavor').index('muon').label = r'$\mu$ Flavor'
pthist.axis('flavor').index('pseudodata').label = r'Pseudodata from e/$\mu$'
# using regular expressions on flavor name to select just the data
# another method would be to fill a separate data histogram
import re
notdata = re.compile('(?!pseudodata)')
[34]:
# make a nice ratio plot, adjusting some font sizes
plt.rcParams.update({
'font.size': 14,
'axes.titlesize': 18,
'axes.labelsize': 18,
'xtick.labelsize': 12,
'ytick.labelsize': 12
})
fig, (ax, rax) = plt.subplots(
nrows=2,
ncols=1,
figsize=(7,7),
gridspec_kw={"height_ratios": (3, 1)},
sharex=True
)
fig.subplots_adjust(hspace=.07)
# Here is an example of setting up a color cycler to color the various fill patches
# We get the colors from this useful utility: http://colorbrewer2.org/#type=qualitative&scheme=Paired&n=6
from cycler import cycler
colors = ['#a6cee3','#1f78b4','#b2df8a','#33a02c','#fb9a99','#e31a1c']
ax.set_prop_cycle(cycler(color=colors))
fill_opts = {
'edgecolor': (0,0,0,0.3),
'alpha': 0.8
}
error_opts = {
'label': 'Stat. Unc.',
'hatch': '///',
'facecolor': 'none',
'edgecolor': (0,0,0,.5),
'linewidth': 0
}
data_err_opts = {
'linestyle': 'none',
'marker': '.',
'markersize': 10.,
'color': 'k',
'elinewidth': 1,
}
# plot the MC first
hist.plot1d(
pthist[notdata],
overlay="flavor",
ax=ax,
clear=False,
stack=True,
line_opts=None,
fill_opts=fill_opts,
error_opts=error_opts
)
# now the pseudodata, setting clear=False to avoid overwriting the previous plot
hist.plot1d(
pthist['pseudodata'],
overlay="flavor",
ax=ax,
clear=False,
error_opts=data_err_opts
)
ax.autoscale(axis='x', tight=True)
ax.set_ylim(0, None)
ax.set_xlabel(None)
leg = ax.legend()
# now we build the ratio plot
hist.plotratio(
num=pthist['pseudodata'].sum("flavor"),
denom=pthist[notdata].sum("flavor"),
ax=rax,
error_opts=data_err_opts,
denom_fill_opts={},
guide_opts={},
unc='num'
)
rax.set_ylabel('Ratio')
rax.set_ylim(0,2)
# add some labels
coffee = plt.text(0., 1., u"☕",
fontsize=28,
horizontalalignment='left',
verticalalignment='bottom',
transform=ax.transAxes
)
lumi = plt.text(1., 1., r"1 fb$^{-1}$ (?? TeV)",
fontsize=16,
horizontalalignment='right',
verticalalignment='bottom',
transform=ax.transAxes
)
Some further styling tools are available through the mplhep package. In particular, there are several stylesheets that update plt.rcParams to conform with experiment style recommendations regarding font face, font sizes, tick mark styles, and other such things. Below is an example application.
[35]:
import mplhep
plt.style.use(mplhep.style.ROOT)
# Compare this to the style of the plot drawn previously
ax = hist.plot1d(lepton_pt, overlay="flavor", density=True)